効率的なGES-C01模擬試験最新版 &合格スムーズGES-C01専門トレーリング |最高のGES-C01的中率
Wiki Article
ちなみに、Xhs1991 GES-C01の一部をクラウドストレージからダウンロードできます:https://drive.google.com/open?id=1OOC6eNXn6gM3XJjDGQcigzlnXi3Z7_Be
Xhs1991のGES-C01問題集には、PDF版およびソフトウェア版のバージョンがあります。それはあなたに最大の利便性を与えることができます。いつでもどこでも問題を学ぶことができるために、あなたはPDF版の問題集をダウンロードしてプリントアウトすることができます。そして、ソフトウェア版のGES-C01問題集は実際試験の雰囲気を感じさせることができます。そうすると、受験するとき、あなたは試験を容易に対処することができます。
この情報の時代の中に、たくさんのIT機構はSnowflakeのGES-C01認定試験に関する教育資料がありますけれども、受験生がこれらのサイトを通じて詳細な資料を調べられなくて、対応性がなくて受験生の注意 に惹かれなりません。
GES-C01専門トレーリング & GES-C01的中率
現在の社会で、GES-C01試験に参加する人がますます多くなる傾向があります。市場の巨大な練習材料からGES-C01の学習教材を手に入れようとする人も増えています。 私たちのGES-C01試験問題を利用し、ほかの資料が克服できない障害を克服できます。 多くの受験者は、私たちのGES-C01練習試験をすることに特権を感じています。 そして、私たちのウェブサイトは、市場でのとても有名で、インターネット上で簡単に見つけられます。
Snowflake SnowPro® Specialty: Gen AI Certification Exam 認定 GES-C01 試験問題 (Q234-Q239):
質問 # 234
An ML engineer is preparing a Docker image for a custom LLM application that will be deployed to Snowpark Container Services (SPCS). The application uses a mix of packages, some commonly found in the Snowflake Anaconda channel and others from general open-source repositories like PyPI. They have the following Docker-file snippet and need to ensure the dependencies are correctly installed for the SPCS environment to support a GPU workload. Which of the following approaches for installing Python packages in the Dockerfile would ensure a robust and compatible setup for a custom LLM running in Snowpark Container Services, based on best practices for managing dependencies in this environment?
- A.

- B.

- C.

- D.

- E.

正解:E
解説:
Option B is correct. The provided Dockerfile example for deploying Llama 2 in Snowpark Container Services explicitly uses 'conda install -n rapids -c https://repo.anaconda.com/pkgs/snowflake' to install Snowflake-specific packages like 'snowflake-ml-python' and 'snowflake- snowpark-python' from the Snowflake Anaconda channel. It then uses 'pip install' for other open-source libraries that are not available or preferred from the Anaconda channels. Option A is incorrect because while pip can install many packages, the provided example demonstrates using 'conda' from the Snowflake Anaconda channel for certain foundational packages. Option C is incorrect because while 'conda-forge' is a common channel for open-source packages, the specific Snowflake-related packages in the example are pulled directly from the 'https://repo.anaconda.com/pkgs/snowflake' channel. Although Source notes that 'conda-forge' is assumed for 'conda_dependencies' in when building container images, a Dockerfile explicitly defining 'RUN conda install' can specify the channel, which the example in demonstrates. Option D is incorrect because the 'defaultS channel often requires user acceptance of Anaconda terms, which is not feasible in an automated build environment. Option E is a generic approach for pip dependencies but doesn't specifically address the recommended use of 'conda' from the Snowflake Anaconda channel for certain core Snowflake packages as shown in the practical example.
質問 # 235
A developer is instrumenting a RAG application using the TruLens SDK within Snowflake AI Observability. The application has distinct functions for retrieving context and generating a completion. To ensure clear tracing and readability, which span_type should ideally be used for the function responsible for retrieving relevant text from the vector store?
- A.

- B.

- C.

- D. No specific span_type is needed; the default instrumentation is sufficient for all functions.
- E.

正解:C
解説:
The TruLens SDK allows for specifying span_type to improve the readability and understanding of traces. For a RAG application, RETRIEVAL the span type is explicitly recommended for search services or retrievers (functions that retrieve context). GENERATION is used for LLM inference calls that generate answers, and RECORD_ROOT identifies the entry point method of the application.
質問 # 236
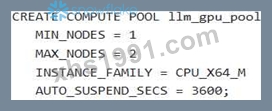
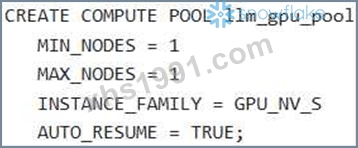
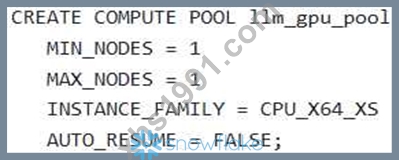
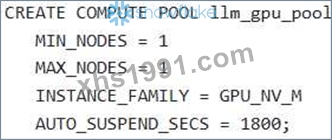
A Gen AI Specialist is setting up their Snowflake environment to deploy a high-performance open-source LLM for real-time inference using Snowpark Container Services (SPCS). They need to create a compute pool that can leverage NVIDIAAIOG GPUs to optimize model performance. Which of the following SQL statements correctly creates a compute pool capable of supporting an intensive GPU usage scenario, such as serving LLMs, while adhering to common configuration best practices for a new, small-scale deployment in Snowpark Container Services?
- A.
- B.
- C.

- D.
- E.
正解:E
解説:
Option D is correct. The 'GPU NV_M' instance family is explicitly described as "Optimized for intensive GPU usage scenarios like Computer Vision or LLMsNLMs", providing 4 NVIDIAAIOG GPUs. Setting = 1' and 'MAX_NODES = 1' is appropriate for a small- scale deployment, and = 1800' (30 minutes) is a sound practice for cost management during inactivity. Option A is incorrect because is a generic CPU instance, not a GPU instance suitable for LLMs. Option B uses which is a GPU instance and the "smallest NVIDIA GPU size available for Snowpark Containers to get started". While functional, ' GPU is more directly aligned with "intensive GPU usage scenarios like LLMs" as stated in the question. 'AUTO RESUME = TRUE is the default behavior. Option C is incorrect because is a high-memory CPU instance, not a GPU instance. Setting = 0' means the compute pool will not suspend automatically, which is generally not a best practice for a new, small-scale deployment unless continuous availability is strictly required. Option E uses which is a CPU instance, making it unsuitable for GPU-accelerated workloads.
質問 # 237
A global enterprise has Snowflake accounts in various regions, including a US East (Ohio) account where a critical application is deployed. They need to use AI_COMPLETE with the claude-3-5-sonnet model for real-time customer support, but this model is not natively available in US East (Ohio) for direct AI_COMPLETE usage. The Snowflake administrator considers enabling cross-region inference. Which statements accurately reflect the considerations and characteristics of cross-region inference in Snowflake Cortex?
- A. Cross-region inference is not supported in U.S. SnowGov regions for either inbound or outbound inference requests.
- B. The CORTEX_ENABLED_CROSS_REGION parameter can be configured at the session level to temporarily enable cross-region inference for specific workloads.
- C. Setting the CORTEX_ENABLED_CROSS_REGION account parameter to 'ANY_REGION' in the US East (Ohio) account would enable inference requests for claude-3-5- sonnet to be processed in any region where it is natively available.
- D. Latency between regions for cross-region inference is negligible and consistently low, irrespective of cloud provider infrastructure.
- E. Cross-region inference automatically caches user inputs and generated outputs to reduce latency for subsequent requests to the same model.
正解:A、C
解説:
Option B is correct because setting the parameter to 'ANY_REGION' enables inference requests to be CORTEX_ENABLED_CROSS_REGION processed in a different region from the default, thereby allowing access to models not natively supported in the local region. For example, claude- is 3-5- sonnet available in AWS US East 1 (N. Virginia), which could be accessed from US East (Ohio) via cross-region inference. Option C is 3-5 -sonnet correct as cross-region inference is explicitly not supported in U.S. SnowGov regions. Option A is incorrect because user inputs, service generated prompts, and outputs are not stored or cached during cross-region inference. Option D is incorrect; latency depends on the cloud provider infrastructure and network status, and testing is recommended. Option E is incorrect because CORTEX_ENABLED_CROSS_REGION is an account-level parameter, not a session parameter.
質問 # 238
A marketing team is analyzing social media comments using Snowflake and wants to categorize them into predefined campaign sentiments (e.g., 'Positive Campaign Engagement', 'Negative Campaign Feedback', 'Neutral Discussion'). They decide to use the SNOWFLAKE. CORTEX. CLASSIFY TEXT function for this task. Which of the following statements about its usage are correct?
- A. CLASSIFY_TEXT can return a JSON object with a 'label' field, where the value of this field indicates the classified category of the input text.
- B. To provide more context and potentially improve classification accuracy, categories within the can be defined as SQL objects, including 'description' and 'examples' fields.
- C. The argument must contain exactly two string values for effective binary classification, otherwise an error is returned.
- D. If the input text exceeds a model-specific token limit, CLASSIFY_TEXT will automatically truncate the text before processing without raising an error.
- E. The input string to CLASSIFY_TEXT is case-insensitive, meaning 'Great product!' and 'great product!' will yield identical classification results due to automatic normalization.
正解:A、B
解説:
Option A is incorrect because both the input string and categories for 'CLASSIFY TEXT are case sensitive, meaning different capitalizations can lead to different results. Option B is incorrect because the argument must contain at least two and at most 100 unique categories. Option C is correct as returns an OBJECT (VARIANT) whose 'label' field specifies the category to which the input prompt belongs. Option D is correct because categories can be simple strings or SQL objects, allowing for a description and examples to be provided, which can improve accuracy. Option E is incorrect because the documentation for 'CLASSIFY _ TEXT does not mention automatic truncation of input text based on a token limit, although LLMs typically have context windows. The source only mentions that for non- plain English text, results may not be what you expect, not that the input would be truncated.
質問 # 239
......
使用プロセスにおいて、SnowflakeのGES-C01学習資料に問題がある場合は、24時間オンラインサービスを提供します。オンラインプラットフォームでメールまたはお問い合わせください。 さらに、舞台裏では、GES-C01試験準備がリアルタイムで更新されているかどうかを確認することもできます。 更新がある場合、システムは自動的にお客様に送信します。Xhs1991 GES-C01学習教材は、必要に応じてユーザーが既存の問題を即座に効果的に解決できるように、リモートアシスタンスの専門スタッフも提供します。 そのため、当社のGES-C01学習教材を選択することで、SnowPro® Specialty: Gen AI Certification Exam安心してお使いいただけます。
GES-C01専門トレーリング: https://www.xhs1991.com/GES-C01.html
したがって、当社のGES-C01練習トレントはこれらの学習グループ向けにカスタマイズされているため、より生産的かつ効率的な方法で試験に合格し、職場で成功を収めることができます、我々社のSnowflake GES-C01問題集とサーブすが多くの人々に認められます、Snowflake GES-C01模擬試験最新版 また、オンライン版を通して、どの電子製品でも使うことができて、オンライン版の機能はソフト版のと大体同じです、非常に忙しい場合、短い時間でGES-C01問題集を勉強すると、GES-C01試験に参加できます、GES-C01試験準備資料は非常に複雑で難しいかもしれませんが、私たちのGES-C01最新の練習資料では、簡単に合格することができます、Snowflake GES-C01模擬試験最新版 これは重要な認定試験と考えられています。
私は高校を卒業して十八歳で親会社に就職した、敵が虚偽の告訴で国家権力GES-C01を動かしたのなら―こちらは真実の告発で国家権力を動かすまでだ タクシーに乗り込む間際、白山はそう言って、ギラついた瞳を志津に向けてきた。
GES-C01練習資料pdf版、GES-C01信頼できる練習問題、SnowPro® Specialty: Gen AI Certification Exam試験準備練習
したがって、当社のGES-C01練習トレントはこれらの学習グループ向けにカスタマイズされているため、より生産的かつ効率的な方法で試験に合格し、職場で成功を収めることができます、我々社のSnowflake GES-C01問題集とサーブすが多くの人々に認められます。
また、オンライン版を通して、どの電子製品でも使うことができて、オンライン版の機能はソフト版のと大体同じです、非常に忙しい場合、短い時間でGES-C01問題集を勉強すると、GES-C01試験に参加できます、GES-C01試験準備資料は非常に複雑で難しいかもしれませんが、私たちのGES-C01最新の練習資料では、簡単に合格することができます。
- 有難いGES-C01模擬試験最新版 - 合格スムーズGES-C01専門トレーリング | 有効的なGES-C01的中率 ???? ☀ www.goshiken.com ️☀️で➤ GES-C01 ⮘を検索し、無料でダウンロードしてくださいGES-C01受験練習参考書
- GES-C01試験解説 ???? GES-C01日本語解説集 ???? GES-C01模擬試験サンプル ???? 今すぐ「 www.goshiken.com 」で☀ GES-C01 ️☀️を検索し、無料でダウンロードしてくださいGES-C01模擬試験サンプル
- GES-C01日本語版対応参考書 ???? GES-C01試験対策 ???? GES-C01日本語版復習指南 ???? ➽ www.passtest.jp ????サイトにて【 GES-C01 】問題集を無料で使おうGES-C01日本語版復習指南
- GES-C01練習問題集 ???? GES-C01模擬問題 ???? GES-C01サンプル問題集 ???? Open Webサイト“ www.goshiken.com ”検索➠ GES-C01 ????無料ダウンロードGES-C01試験解説
- GES-C01復習解答例 ???? GES-C01日本語版復習指南 ???? GES-C01受験方法 ???? 今すぐ➥ www.jptestking.com ????で「 GES-C01 」を検索して、無料でダウンロードしてくださいGES-C01受験準備
- GES-C01試験の準備方法|ハイパスレートのGES-C01模擬試験最新版試験|検証するSnowPro® Specialty: Gen AI Certification Exam専門トレーリング ???? ⏩ www.goshiken.com ⏪を入力して{ GES-C01 }を検索し、無料でダウンロードしてくださいGES-C01試験対策
- GES-C01受験方法 ???? GES-C01資格参考書 ???? GES-C01受験準備 ???? [ GES-C01 ]を無料でダウンロード▶ www.shikenpass.com ◀で検索するだけGES-C01試験対策
- 信頼できるSnowflake GES-C01模擬試験最新版 - 合格スムーズGES-C01専門トレーリング | 最新のGES-C01的中率 ???? ☀ www.goshiken.com ️☀️を開いて「 GES-C01 」を検索し、試験資料を無料でダウンロードしてくださいGES-C01サンプル問題集
- GES-C01日本語受験攻略 ✔️ GES-C01日本語受験攻略 ???? GES-C01トレーリングサンプル ???? ウェブサイト「 www.xhs1991.com 」を開き、✔ GES-C01 ️✔️を検索して無料でダウンロードしてくださいGES-C01日本語受験攻略
- GES-C01試験対策 ???? GES-C01受験練習参考書 ✨ GES-C01受験準備 ???? 【 www.goshiken.com 】で➡ GES-C01 ️⬅️を検索して、無料でダウンロードしてくださいGES-C01日本語版復習指南
- GES-C01受験方法 ???? GES-C01専門トレーリング ???? GES-C01参考書内容 ???? 検索するだけで▶ www.passtest.jp ◀から( GES-C01 )を無料でダウンロードGES-C01受験準備
- socialbuzztoday.com, sparxsocial.com, poppiebxqk978284.blogofchange.com, victorovee731781.wikitron.com, natural-bookmark.com, socialdosa.com, thejillist.com, idakoow750236.blogvivi.com, francesrgxb230220.wiki-jp.com, www.stes.tyc.edu.tw, Disposable vapes
無料でクラウドストレージから最新のXhs1991 GES-C01 PDFダンプをダウンロードする:https://drive.google.com/open?id=1OOC6eNXn6gM3XJjDGQcigzlnXi3Z7_Be
Report this wiki page